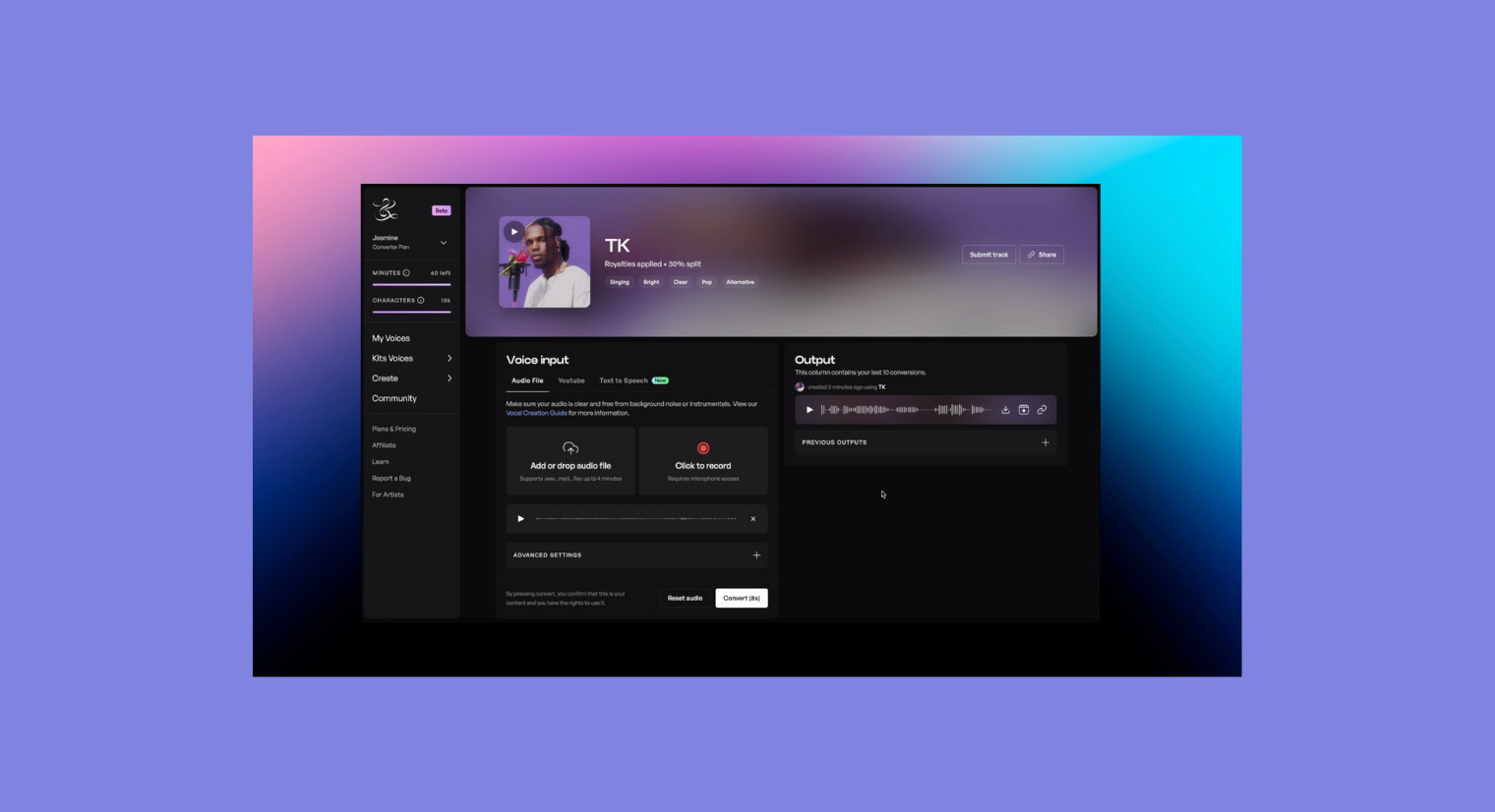
またまた、とんでもないAIツールが登場しました。
まだ、あまり騒がれていないのが不思議ですが、この「Kits.AI」はボーカルやナレーションなどのあらゆる「声」をコピーし、再現できるサービスです。
昨年ヤマハが、誰でもELTの持田香織になれるマイク「TransVox」を発表して話題にもなりましたが、これをついに個人でも利用できるようになったのです。
僕は歌があまり上手くないので、自分の声を曲に入れるなんて微塵も考えたことがなかったのですが、「Kits.AIがあれば、ボーカルを入れるのもアリだな…」と思うようになりました。
上の動画のようにリアルタイムで歌声を変換することはできないものの、精度はかなり高く、実用で十分に使えるレベルです。(実際、僕はすでに映画のお仕事で使っています。)
そんな魅惑の次世代AIツール、Kits.AIの全貌を紐解いていきましょう。
Kits.AIにできること
基本的には、Kits.AIは次の手順で使います。
- 好きなボーカリストやナレーターの声をAIに読み込ませる
- 数十分〜数時間かけて、声の解析が行われる
- 自分のボーカル・ナレーションを録音する
- 自分の声をKits.AIにアップロードすれば、自分の声が、先ほど解析した声になる
ひとたび、好きなボーカリストのAI、例えば「ビョークAI」を作ってしまえば、いつでも自分の歌声をビョークに変換することができます。
AIに読み込ませる声データが正確かつ、長時間であればあるほど、出てくるAIモデリングの精度も上がります。(「正確」というのはノイズが少なく、リバーブやディレイなどのエフェクトが入っていない状態です。「無料AIボイスモデル作成ガイド」にどのような音声ファイルが望ましいのかが書かれているので、参考にしてみてください。)
「好きなボーカリストの声だけのデータなんて持ってないよ…」という場合も、心配する必要はありません。
最近、新たに追加された機能「Voice Separator」を使えば、楽曲から声のみを抽出することができるので、他のサービスを使わずともAIモデリング作成のための下準備ができてしまうのです。
ボーカル抽出ソフトは市場にいくつかありますが、iZotope RXなどを持っている方はそちらを使っても良いですし、以前に紹介した「LALAL.AI」ならボーカル分離精度がかなり高いので、こちらを使っても良いでしょう。
参考: iZotope RXを超えた?LALAL.AIのボーカル分離技術がすごい – スタジオ翁
Kits.AIにできる5つのこと
Kits.AIはかなり多機能で、上に挙げた「AIモデル作成」「Voice Separator」以外にも、いくつかの便利な機能があります。
1. 声を楽器に変換する
Kits.AIにできるのは、好きなボーカリストの声を再現することだけではありません。
なんと、自分の声をいろんな楽器に変換することもできるので、楽器を弾かずとも「好きなメロディーを歌い、それをサックスに演奏させる」なんてことも可能なのです。
楽器の種類は、サックス、ギター、チェロ、ベースなどがあります。
リアルタイムで変換するなら、最近よく広告で見かける「Dubler 2」の方が使いやすいかもしれません。
2. テキストからAIボイスを作成する
作成したAIボイスに、テキストを喋らせることもできます。
今のところ、英語のみの対応となっていますが、「Coming Soon」となっているので、そのうち日本語にも対応するようになるかもしれませんね。
3. YouTubeのリンクから直接AIモデルを作成する
これは、かなり便利なのではないでしょうか。
わざわざ音声ファイルを準備しなくても、YouTubeのリンクを貼るだけでAIモデルを作成することができます。
ただし、動画に声以外の音が入っているとおそらく精度が落ちるので、声だけがしっかり入っている動画を選ぶ必要がありそうです。
4. 著作権フリーのボイスライブラリ
種類は少ないですが、著名アーティストの声をクローン化したと思われる、いくつかの公式ライブラリがあります。
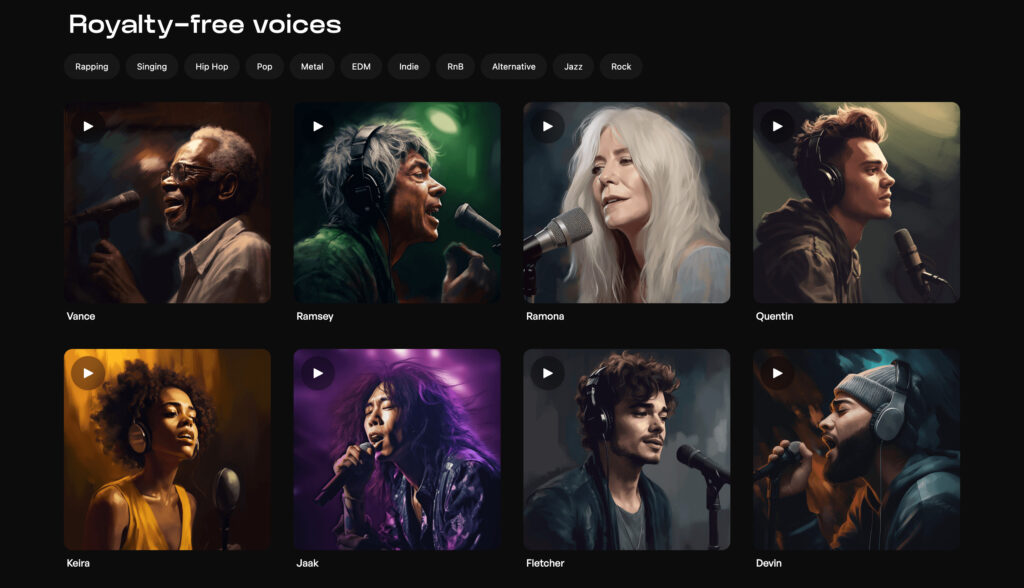
公式なので、精度はかなり良いと思います。
好きなアーティストの声があれば、こちらから試してみるのも良いかもしれません。
5. コミュニティーライブラリでAIモデルをシェア
下の画像を見ての通り、海外のいろんな人が著名人の声をクローン化して公開しています。
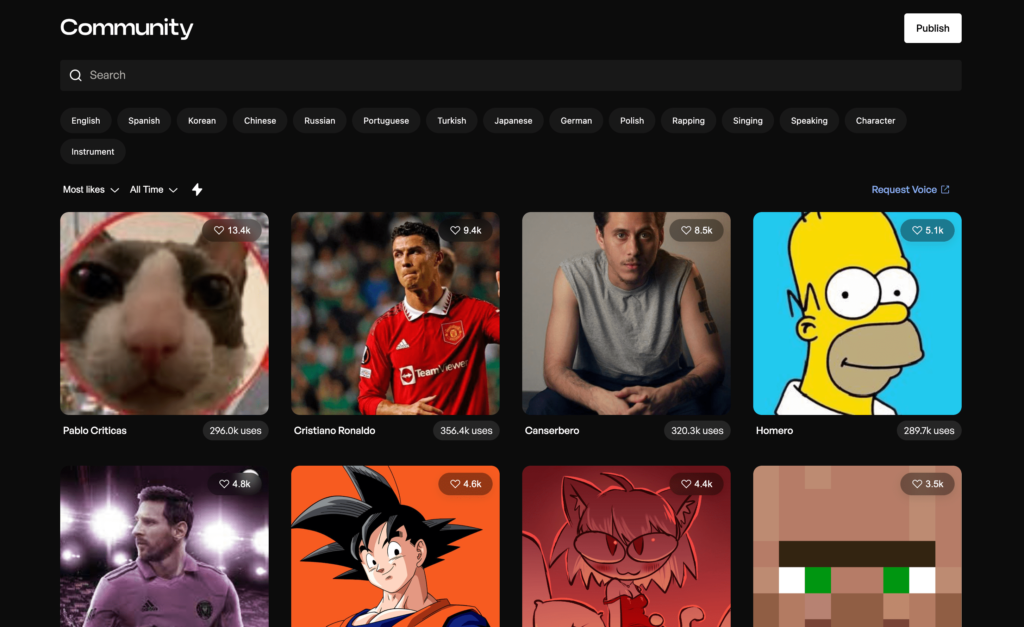
ドラゴンボールの悟空もありますが、こちらはスペイン語でAIモデリングされているので、日本語を変換しても再現性の低い謎の声になってしまうので気をつけましょう。
日本語からAIモデリングされたものなら、日本語で話して変換すれば、ちゃんと自然な発音の日本語に変換されるのでご安心ください。
Kits.AIの料金プラン
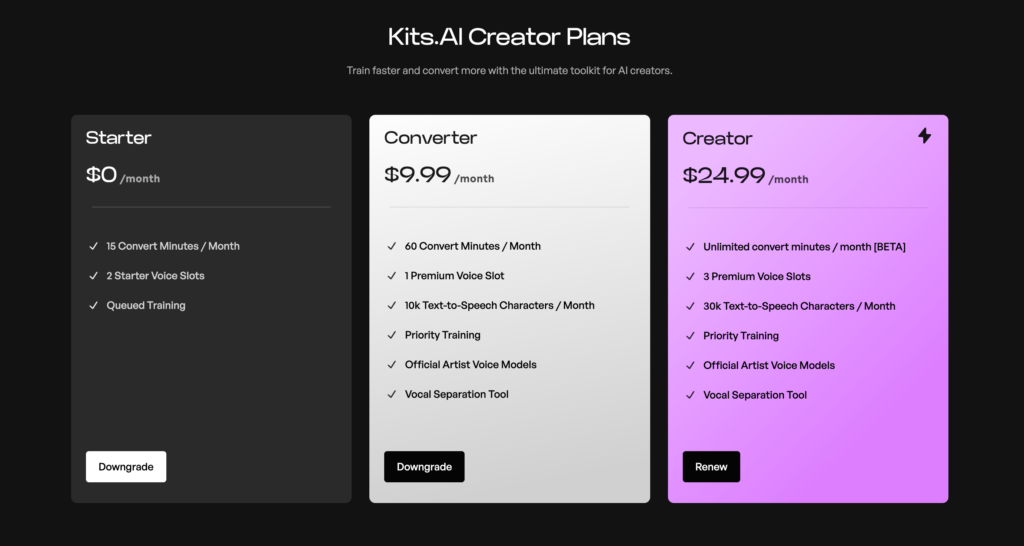
プランは、「Starter(無料)」「Converter」「Creator」の3種類があります。
多少の制限はあるものの、無料プランでも十分にクオリティの高いAIモデルを作ることができます。
有料プランになると、AIに学習させられる時間数が15分から1時間に増えるので、より精度の高いAIモデルを作れます。
実際にフリープランも試してみて、15分の学習でも上手くAIモデルが作れる場合もありましたが、やはりAIに学習させるサンプルや時間数は多ければ多いほど正確になりますね。
月24.99ドルのCreatorプランだと、無制限にAIボイス変換ができるようになるので、時間制限を気にせず使いたい方は最上位の「Creator」を選ぶと良いでしょう。
Kits.AIを使いこなすための3つのコツ
以前、仕事でどうしてもKits.AIを使わないといけない状況があったので、これを使いこなすためにいろいろ試行錯誤を繰り返しました。
その中で、どうすれば上手くAIクローンが作れるのかがわかってきたので、そのコツをご紹介したいと思います。
1. イントネーションや滑舌までは再現できない
まず、大前提として、Kits.AIでクローン化できるのは「声質」のみです。
多少の滑舌やイントネーションはAIボイスに反映されるのですが、声質以外の要素は、自分の声で録音する時に意識的に似せる必要があります。
適当に喋っても良い結果は得られないので、ナレーションなら「滑舌よく喋る」、ボーカルなら「ボーカリストに寄せて歌う」というようにしないといけません。
なので、喋りがめちゃくちゃ下手だったり、歌が下手で音程が合っていなければ、満足のいく結果を得るのは難しいかもしれませんね。
歌のプロでもない限り、自分のイメージしている声と実際の声にはかなりギャップが出るので、僕の場合は一発録りをせずにパートごとに録音したものをつなぎ合わせるようにしました。
2. ピッチシフトを上手く使う
Kits.AIにはピッチを変更できる機能がついているので、これを上手く活用しましょう。
例えば、男性が女性のAIボイスを使う時は1オクターブ上げ(12セミトーン)、女性が男性のAIボイスを使う時は1オクターブ下げに設定しておきます。
セミトーンごとの調整ができるので、イメージと微妙に違っている場合は、1~2セミトーンの調整をしても良いかもしれません。
こうすれば、性別が違っても綺麗に声を変換することができるので、ぜひ試してみてください。
3. マニュアルを参考に音を整えておく
先ほど紹介した無料AIボイスモデル作成ガイドを読み、AIに学習させる音声を整えておくと、良い結果が得られることが多いです。
英語なので、概要をこちらにまとめておきます。
- リバーブ、ディレイ、コーラス、インストゥルメンタルなし – ハーモニー、レイヤー、ダブルトラッキング、ステレオエフェクトはなし
- 最良の結果を得るためには、異なるボーカル・スタイル(歌とラップなど)用に異なるモデルを作成する
- 余分な無音部分を削除する(Audacityなどを使う)
- モノラルとして書き出す(LとRのチャンネルが等しいステレオではなく)
- 16ビットの.wavとして書き出す(オーディオの長さの規定はありません)
- バックグランドノイズ、plosivesなどを除去するためにクリーンアップする(Ultravocalremovergui)
- クリーンEQ(減算方式)で、レコーディングの濁った周波数やきつい周波数を抑える
- ヴォーカル・スタイルの重要な部分でない限り、微妙にピッチを補正する(ゆっくりしたアタック、適度な強さ)
- 厳しいシビランスを低減するためのディエッシング
- ダイナミック・レンジを均等にし、ピークを減らすために軽くコンプレッションする(最大でも4~5dbのゲインリダクション)
- ボーカルのスタイルに合わせてブースト(加算EQ)する
- ピークは-6db、全体のレベルは-6~-12dbにする
- 40hz~100hz以下と20khz以上の周波数を除去するためにハイ/ローパスする
経験上、余計な音やノイズなどが入っていると、最終的なアウトプットにノイズなどが入ってしまうので、AIモデルを作成するときは、なるべく綺麗な録音のみを使うようにしましょう。
また、AIモデルを作るコツとして、このようなことも書かれています。
種類が多ければ多いほどいい。 全音域をカバーする例があるのがベスト。チェスト、ミックス、ファルセット、大きな音程と短い音程、硬い音ときれいな音など。バラエティに富んでいればいるほどいい。 同じ歌詞を違うキーで歌ってもいいし、レパートリーから2、3曲歌ってもいいし、オリジナル曲でもいい。歌唱時間が10~15分であれば、音声は複数のファイルでも1テイクでも構いません。
https://www.kits.ai/blog/voice-model-creation-guide
特定のフレーズだけを学習させると、特定のフレーズを歌った時にしか上手く変換することができません。
歌い方や読み方にいろんなバリエーションがあると、その分だけ、より自然な結果になるでしょう。
まとめ

Kits.AIを使いこなすには、多少時間をかける必要がありますが、慣れてしまえば思い通りにAIクローンを作って自分の歌声を変換することができるようになります。
先ほどの章にもまとめましたが、どれだけ下準備をするかでアウトプットのクオリティが変わってくるので、ノイズを取ったり綺麗な録音だけを抜き出したりして、AIに学習させる音を整えておくことが大切です。
自分の歌声に自信がなかったために今までボーカルを入れられなかった人も、次の作品には、Kits.AIを使って声を入れてみてはいかがでしょうか。
音楽制作の新たな可能性が広がるかもしれませんよ。
今日も最後までお読みいただき、ありがとうございました。